Die GPU im Keller: Was passiert, wenn High-End lokal wird? (KW 41, 3.–12.10.2025)
Wenn das der Betriebsrat hört: Frontier-Intelligenz von vor 12 Monaten auf der GPU im Keller. Tool-Budget: 500–1.000 $ pro Engineer für Tools sind günstig – teuer wird es ohne Enablement. Plus: „Vibe Coding“ macht Demos, „Vibe Engineering“ liefert Wert.


Diese Woche legt eine Analyse von Epoch AI nahe, dass semi-offene Modelle auf Einzel-GPUs den Frontier-Stand im Mittel nach 6–12 Monaten erreichen. In ihrer Auswertung zeigen consumer‑taugliche 28–40‑Milliarden‑Parameter‑Modelle auf NVIDIA RTX‑Karten Benchmarkwerte nahe am jeweiligen Spitzenfeld. Was heißt das für Strategie, Budgets und Betrieb, wenn Leistung rasch „nach unten diffundiert“?
Epoch AI verdichten in ihrer Auswertung zum Consumer‑GPU‑Gap mehrere harte Metriken für „allgemeine Intelligenz”, also keine speziellen Benchmarks für Agentic Coding: GPQA‑Diamond, MMLU‑Pro, den Artificial‑Analysis‑Index und Nutzer‑Elo. Die Kernaussage: Mit 4‑bit‑Quantisierung und 8k Kontext passen heute grob 27B‑Modelle in 24 GB Videospeicher (VRAM) und rund 40B in 32 GB. Damit kann eine einzelne High‑End‑Gamingkarte wie die RTX 5090 Modelle ausführen, die dem Frontier‑Niveau von vor 6–12 Monaten entsprechen. Die Autor:innen warnen zugleich vor Benchmarktuning kleiner offener Modelle; der reale Abstand kann länger sein. Trotzdem markiert die Tendenz einen spürbaren Effekt: Frontier‑ähnliche Fähigkeiten werden lokal und bezahlbar. In deutschen Rechenzentren wartet man darauf gern, bis die nächste Gremienrunde durch ist.
"Using a single top-of-the-line gaming GPU like NVIDIA’s RTX 5090 (under $2500), anyone can locally run models matching the absolute frontier of LLM performance from just 6 to 12 months ago."
Lokale Leistung ist nah und hat klare Grenzen
Das Versprechen klingt einfach: Frontier im Keller. Die Details sind es nicht. Ein LLM mit 40 Milliarden Parametern passt bei 4‑bit Quantisierung nur, wenn der Kontext klein bleibt. Der Schlüssel ist der Key Value Cache , der bei 8k Kontext bereits mehrere Gigabyte frisst; Epoch rechnet mit etwa 6,6 GB plus rund 2 GB Laufzeit‑Overhead. Wächst der Kontext, schrumpft die praktisch nutzbare Modellgröße auf einer einzelnen Grafikprozessor‑Karte (Graphics Processing Unit, GPU) deutlich. Offloading in den Hauptspeicher hilft, kostet aber Tempo und Stabilität.
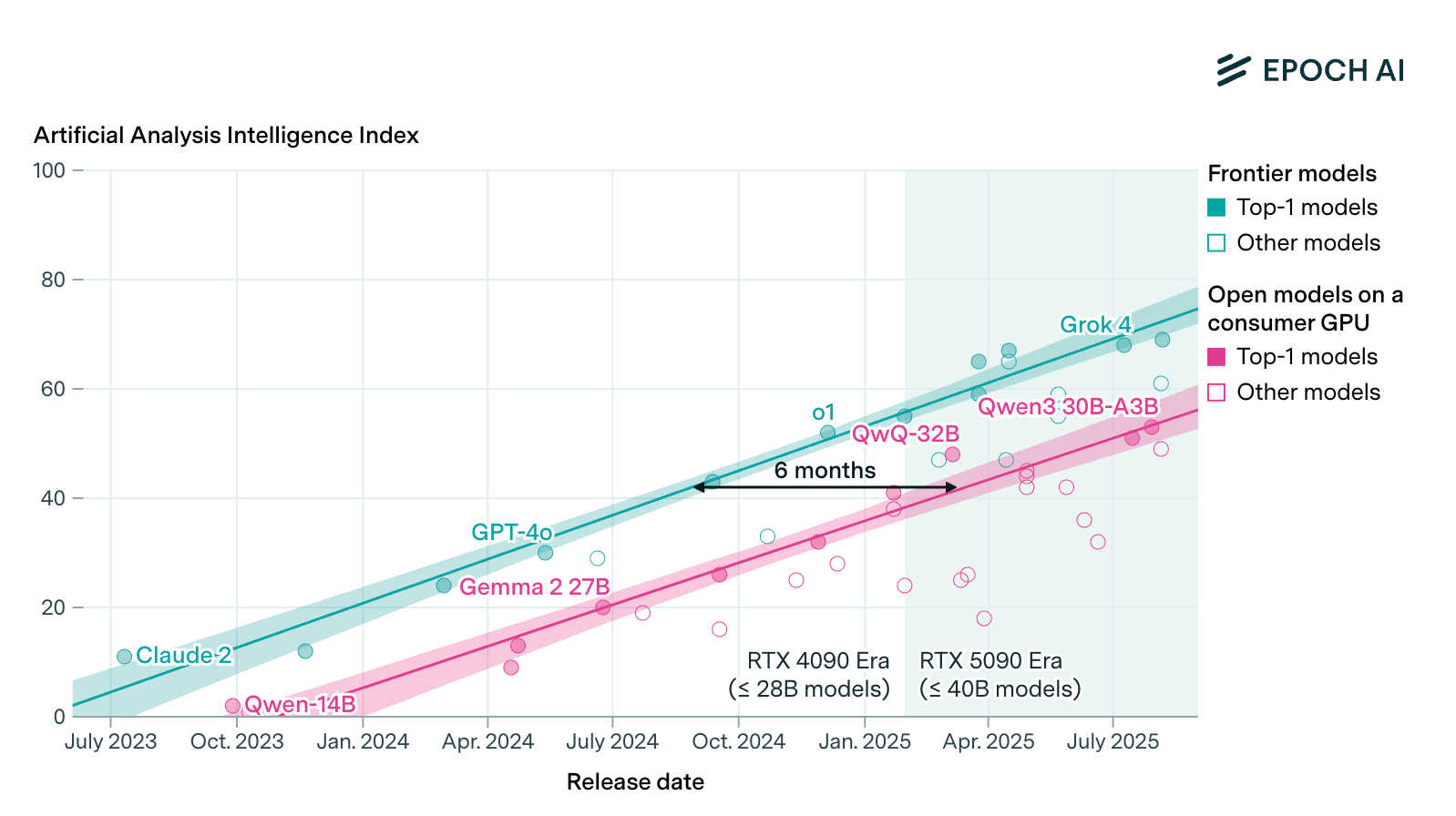
Dazu kommt Qualitätsstreuung: Manche offenen Modelle sind auf GPQA/MMLU‑Pro optimiert. Nutzerinnenpräferenz‑Metriken wie Elo zeichnen ein anderes Bild. Kurz: Lokal wird gut genug, aber nicht State-of-the-art. Eine klare, eigene Evaluierungsroutine trennt Nutzen von Benchmark‑Theater. Ein State of the Art Coding Modell mit min. 128k Kontextfenster für die Entwicklungsabteilung betreibt man nicht einfach so auf der eigenen GPU im Keller. Wer das ignoriert, bekommt hübsche Demos und schwache KI-Systeme.
Absorptionsfähigkeit bauen, nicht nur GPUs kaufen
Stuart Winter‑Tear zitiert Jeff Bezos mit seinem Bahnschienen-Infrastrukturvergleich und nennt das Phänomen eine „positive Bubble“: Überinvestition baut die Schienen, Wert entsteht in Teams, die diszipliniert darauf fahren. Er argumentiert, den Schwerpunkt von Demo‑Feuerwerk auf Aufnahmekapazität zu legen, und verweist auf EROOM’s Law – Erfindung rennt, Adoption hinkt. Seine These liest sich in seinem Beitrag über Absorption statt Hype wie eine ToDo-Liste für 2026: Operating Model, Governance, Evals, „Agents on Rails“ statt Plattformfantasien.
Das deckt sich mit dem spürbaren „Vibe Shift“, den Ethan Mollick beschreibt: Weg von der Wertfrage, hin zur Organisationsarbeit. Ohne Klarheit über Rollen, Prozesse und Abnahmewege verpufft der Technikvorsprung. Seine Beobachtung, dass Agenten oft schon nützlich arbeiten, aber nur eingebettet Wert schaffen, ist hier zentral und lesenswert in seinem Hinweis auf den Führungsjob der Stunde. Kein AI Model ohne Operating Model. Wer weiter auf Einkaufstour für „die eine Plattform“ geht, spart an der einzigen knappen Ressource – Organisationsänderung.
Engineering wird erwachsen: von Vibe Coding zu Vibe Engineering
Der Begriff „Vibe Coding” treibt mittlerweile erfolgreich alle in den Wahnsinn. Von Engineers im Widerstand wird er abfällig (und falsch) als Mantelbegriff für jede Form von Zusammenarbeit mit KI im Coding benutzt, um ihre Verachtung der Technologie gegenüber auszudrücken. Simon Willison versucht nun anzuerkennen, dass der Begriff „Vibe” für den Umgang mit KI im Engineering nicht mehr aus der Welt zu kriegen ist. Er coined also „Vibe Engineering“ als seniorige Praxis mit LLM‑Agenten: Tests, Spezifikationen, Dokumentation, CI/CD und Code‑Review sind keine Zierde, sondern Geländer. In seinem Beitrag über reifes Arbeiten mit Coding‑Agenten formuliert er die Verantwortungsverschiebung klar.
AI tools amplify existing expertise.
Das hat zwei Folgen. Erstens: Tests und sauberer Git‑Workflow werden zu Produktionshebeln; Agenten beschleunigen dort, wo die Leitplanken stark sind. Zweitens: Führung wird zur Orchestrierung „digitaler Praktikanten“ – inklusive klarer Erfolgskriterien. Ein nüchterner Blick auf reale Agenten‑Outputraten hilft, etwa mit PR‑Daten aus Projekten wie PRarena. Merge‑Quoten sind keine Qualität, aber ein Trendindikator. Wer hier nicht misst, glaubt.
Programme statt Prompts: Portabilität als Versicherung gegen Sprünge
Die Halbwertszeit der „besten Prompt‑Taktik“ schrumpft. Drew Breunig zeigt am Beispiel POI‑Abgleich in Overture Maps, wie man Aufgaben als Signaturen formuliert und sich Prompts aus Evaluationsdaten generieren lässt. DSPy kapselt Taktiken in Module und optimiert sie pro Modell neu; das erhöht Genauigkeit und hält Systeme portabel. Seine Fallstudie zu DSPy als Prompt‑Automat zeigt deutliche Genauigkeitsgewinne bei kleinen Modellen – mit handhabbaren Evalsets.
Don’t program your prompt. Program your program.
Für den Betrieb heißt das: EvalOps (Evaluierungs‑Betrieb) gehört in den Alltag wie Unit‑Tests. Aufgaben, Beispiele, Metriken und Artefakte versionieren, regelmäßig neu optimieren, und Modelle wechseln, wenn Preis/Leistung kippt.
Budgets 2026: Mehr Messung, weniger Mythos
Leistung wandert nach unten, Preise wandern nach oben. In einem nüchternen Gespräch über Budgetrahmen empfiehlt Laura Tacho, pro Entwicklerin mindestens 500–1.000 US‑Dollar jährlich für KI‑Tooling einzuplanen – plus Mittel für Messung und Enablement. Das Gespräch zu Benchmarks, Kostenkontrolle und ROI setzt klare Prioritäten: Multi‑Vendor statt Lock‑in, datengetriebene Piloten, ROI über Team‑Workflows statt nur individuelle Beschleunigung. Das passt zur Consumer‑GPU‑Tendenz: Mehr lokal, mehr Experimente, mehr Verantwortung beim eigenen Team. Wer den Budgetpitch als „Kostensenkung“ framet, bekommt am Ende nur einen kleineren Topf.
Die operative Konsequenz: Tiefe, vertikale Schnitte statt großer Agenten-Plattformträume; Metriken, die Verhalten steuern; ein geerdetes Sicherheitsmodell; kontinuierliche Evals; Wiederverwendung statt Einzelfallkunst. Mit der absehbaren Leistungsdiffusion auf Consumer‑Hardware wird nicht die eine Wahl entscheidend, sondern unsere Fähigkeit, sie zu wiederholen.
Wenn Frontier‑ähnliche Fähigkeiten innerhalb von einem Jahr auf unseren GPUs landen, gewinnt nicht, wer das größte Modell kauft, sondern wer mit klaren Leitplanken schnell lernt und konsequent evaluiert.